Biblical Mathematical Verification
A Python statistics script verifying the numeric pattern theories of Ivan Panin in biblical manuscripts through letter value arrays.
Biblical Mathematical Verification
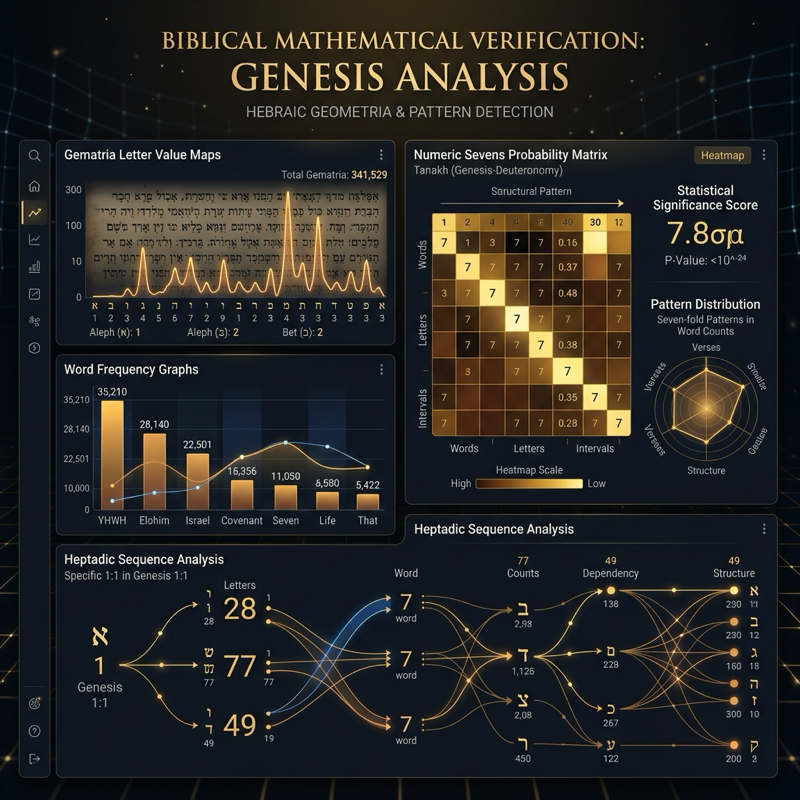
This project is a statistical analysis tool written in Python that evaluates the controversial mathematical claims of Ivan Panin regarding the design of the Bible’s original Greek and Hebrew texts. Panin, a 19th-century Russian mathematician, claimed that the scriptures exhibit complex structures of numerical patterns (specifically clusters of the number 7) that are statistically impossible to have occurred by chance or manual compilation.
Gematria & Statistical Fingerprinting
Panin’s theories rely on the fact that ancient Greek and Hebrew do not have separate numerical characters. Instead, letters of their alphabets double as numbers (Gematria). Every letter has a fixed numerical value (e.g., in Greek: Alpha = 1, Beta = 2, Theta = 9, etc.). The numeric value of a word is the sum of the values of its letters.
+-----------------------------------------------------------+
| Manuscript Unicode Parser |
| - Normalizes Greek (Nestle-Aland) / Hebrew (WLC) text |
| - Trims accents, breathing marks, and punctuation |
+-----------------------------------------------------------+
|
v
+-----------------------------------------------------------+
| Numeric Mapping Engine |
| - Maps character arrays to historic Gematria indexes |
| - Sums letter values to calculate word values |
| - Computes sentence and verse totals |
+-----------------------------------------------------------+
|
v
+-----------------------------------------------------------+
| Divisibility & Probability Test |
| - Counts factors of 7 across words, letters, and sums |
| - Runs Monte Carlo simulation against control texts |
| - Outputs probability coefficients (p-values) |
+-----------------------------------------------------------+Key Code Operations
1. Unicode Normalization
To ensure accurate letter counts, the Python parser reads original manuscript databases in UTF-8 format. It normalizes diacritical marks (accents like acute, grave, or circumflex and breathing marks like smooth or rough breathing) which are not part of the basic character numbers, stripping them before processing.
2. Numerical Character Mapping
The script maps each letter to its historical numeric value using a lookup dictionary. It processes arrays of words to return:
- Letter counts per word, sentence, and paragraph.
- Consonant and vowel distributions.
- Cumulative numerical values of text segments.
3. Probability Calculations & Monte Carlo Controls
Panin claimed that finding dozens of features divisible by 7 in a single passage (such as the genealogy in Matthew 1) is astronomically rare. The script runs factors analysis on the text to count these features. It then evaluates this claims by generating randomly ordered scrambled versions of the target passages and calculating the frequency of coincidental numeric structures, evaluating the actual probability score ($p$-value).